Machine learning (ML) stands at the forefront of technological innovation, transforming industries and revolutionizing our interactions with the world. ML drives advancements across various fields, from healthcare to finance, and from customer service to autonomous driving by enabling computers to learn from data and improve performance over time.

Machine learning (ML) is a branch of artificial intelligence (AI) and computer science that focuses on using data and algorithms to enable machines to imitate human learning. This technology allows computers to analyze vast amounts of data, identify patterns, make predictions, and improve their performance over time without being explicitly programmed. The concept of machine learning has its roots in the early days of AI research. Arthur Samuel coined the term 'machine learning' in 1959, describing it as a 'field of study that gives computers the ability to learn without being explicitly programmed.' Since then, the field has evolved significantly, driven by advancements in computing power, the availability of large datasets, and the development of sophisticated algorithms.
At the core of machine learning are algorithms, sets of rules or instructions that the computer follows to learn from data. These algorithms range from simple linear regression models to complex neural networks.
Data fuels machine learning. It can come from various sources, such as text, images, videos, and sensor readings. The quality and quantity of data significantly impact machine learning models' performance.
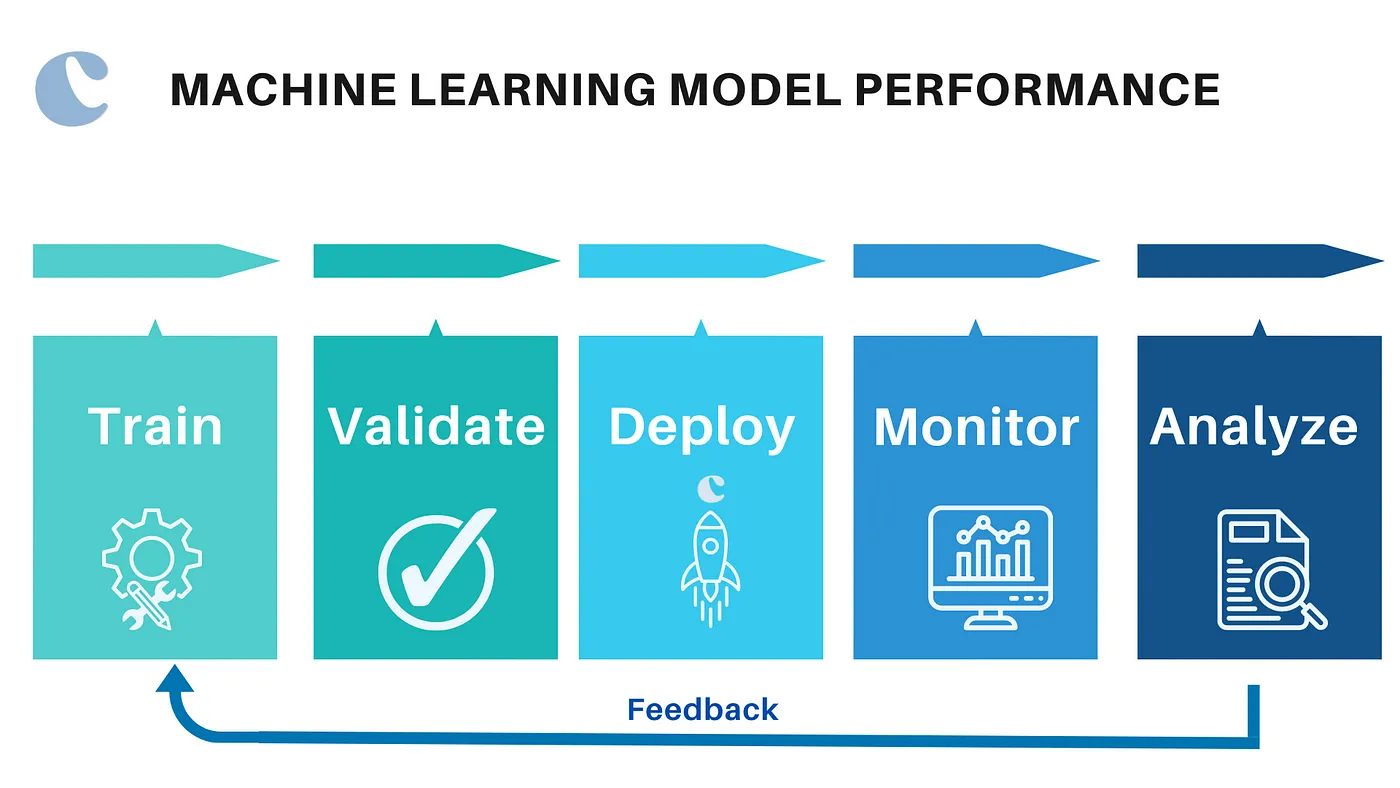
Training a machine learning model involves feeding it data and allowing it to learn patterns and relationships within the data. This process typically involves splitting the data into a training set and a test set to evaluate the model's performance.
In machine learning, the decision process involves making predictions or classifications based on input data. For example, in a recommendation system, the algorithm analyzes user behavior and preferences to suggest products or content. The decision process starts with the input data and produces an output, such as a recommendation or classification.
An error function, also known as a loss function, evaluates the accuracy of the model's predictions. It measures the difference between the predicted output and the actual output. For instance, in a house price prediction model, the error function calculates the difference between the predicted price and the actual selling price. The goal is to minimize this error to improve the model's accuracy.
The model optimization process involves adjusting the model's parameters to minimize the error function. This process is iterative and involves repeatedly evaluating and optimizing the model until it meets a desired level of accuracy. Techniques such as gradient descent are commonly used to adjust the model's weights and biases to reduce the error.
Supervised learning involves training algorithms on labeled datasets, where each input is paired with the correct output. The model learns to map inputs to outputs by analyzing the labeled data, and its performance is evaluated based on how accurately it predicts the labels on new data.
Unsupervised learning algorithms analyze and cluster unlabeled datasets, identifying hidden patterns or groupings without human intervention. This approach is useful for exploratory data analysis and discovering structures within data.
Semi-supervised learning combines aspects of both supervised and unsupervised learning. It uses a small amount of labeled data to guide the learning process from a larger set of unlabeled data. This method is particularly useful when labeled data is scarce or expensive to obtain.
Reinforcement learning involves training an algorithm through trial and error, where it learns to make decisions by receiving rewards or penalties. The model aims to maximize the cumulative reward over time by improving its decision-making strategy.
Neural networks simulate the way the human brain processes information, making them powerful tools for pattern recognition and classification tasks. They consist of layers of interconnected nodes (neurons) that process input data and pass the output to the next layer.
Linear regression is a supervised learning algorithm used to predict numerical values based on a linear relationship between input variables. It is straightforward and interpretable, making it a popular choice for predictive modeling.
Logistic regression is a supervised learning algorithm used for binary classification tasks. It predicts the probability of a binary outcome, such as yes/no or true/false, based on input features.
Clustering algorithms, such as k-means, group data points into clusters based on their similarity. These unsupervised learning methods are useful for exploratory data analysis and finding natural groupings in data.
Decision trees are supervised learning algorithms that split data into branches based on feature values, leading to a decision or classification. Random forests improve decision trees by combining the predictions of multiple trees to reduce overfitting and improve accuracy.
Machine learning powers speech recognition systems, converting spoken language into text. This technology is used in virtual assistants, voice-activated devices, and transcription services.
AI-driven chatbots and virtual agents enhance customer service by providing instant responses to inquiries, personalizing interactions, and handling routine tasks. This improves efficiency and customer satisfaction.
Machine learning enables computers to interpret and understand visual information from images and videos. Applications include facial recognition, medical imaging, and autonomous vehicles.
Recommendation engines use machine learning algorithms to analyze past user behavior and suggest products, services, or content. This technology is widely used in e-commerce, streaming services, and social media.
Financial institutions use machine learning to detect fraudulent activities by analyzing transaction patterns and identifying anomalies that indicate suspicious behavior.
The concept of technological singularity, where AI surpasses human intelligence, raises concerns about control and safety. While most experts agree that superintelligence is not imminent, the possibility prompts important ethical discussions.
The use of large datasets in machine learning raises significant privacy concerns. Ensuring data protection and complying with regulations like GDPR and CCPA are crucial for maintaining user trust.
Machine learning models can inadvertently learn and propagate biases present in training data, leading to unfair and discriminatory outcomes. Addressing bias in AI is critical for developing fair and equitable systems.
The lack of significant regulation in AI development poses challenges in ensuring accountability and transparency. Establishing ethical frameworks and guidelines is necessary to govern the construction and deployment of AI systems.
Machine learning is a powerful tool that is reshaping industries and enhancing our daily lives. From improving customer service and healthcare to driving innovations in autonomous systems and personalized recommendations, its applications are vast and impactful. However, with great power comes great responsibility. Addressing the challenges and ethical considerations of machine learning is essential to ensure its benefits are realized while minimizing potential harm. Concerns about technological singularity, job displacement, privacy, bias, and accountability must be thoughtfully addressed through robust ethical frameworks, regulations, and ongoing dialogue among stakeholders.
Subscribe to get the latest updates and trends in AI, automation, and intelligent solutions — directly in your inbox.
Discover the power of Machine Learning for advanced analytics, predictive modeling, and AI-driven business optimization.
Empower your AI journey with our expert consultants, tailored strategies, and innovative solutions.