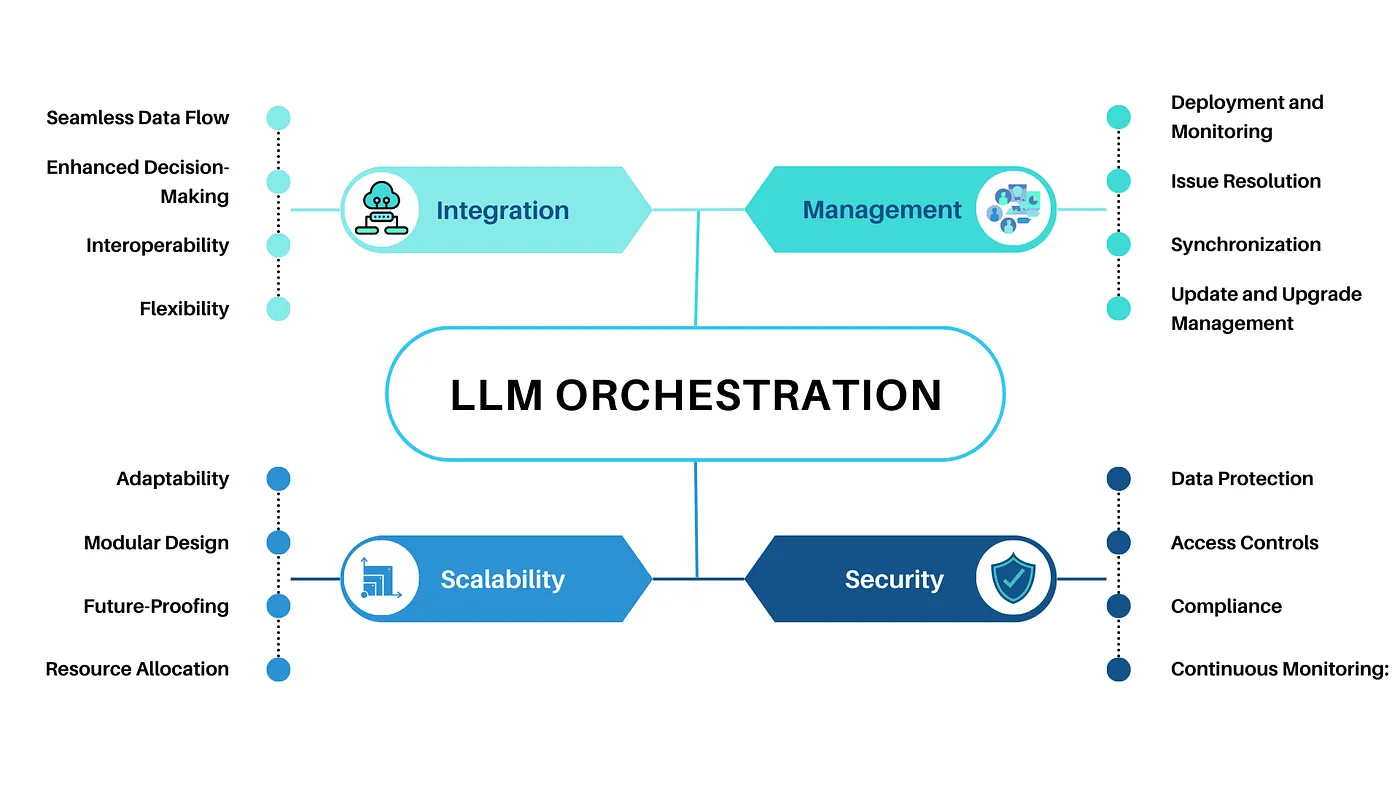
Large Language Models (LLMs) are revolutionizing the field of artificial intelligence, powering applications from chatbots to advanced data analytics. However, these models are prone to generating hallucinations-factually incorrect or nonsensical outputs that can significantly impact the reliability of AI systems. Such cases underscore the need for solutions to ensure the accuracy of AI-powered content.

LLM hallucinations refer to instances where AI models produce outputs that deviate from factual accuracy, often blending incorrect or nonsensical information. These hallucinations occur because LLMs generate text based on patterns and probabilities in their training data without verifying factual correctness.
This occurs when a language model merges information from various sources, leading to a blending of facts that may result in contradictions or the creation of fictional details. For example, if the model combines facts from different historical events or sources inaccurately, it might generate a narrative that includes fictional events or incorrect timelines.
Factual errors arise when the model generates outputs with inaccuracies due to imperfect or outdated training data. For instance, if the model is trained on data that includes incorrect historical facts or outdated scientific knowledge, it might produce text containing these inaccuracies, potentially misleading users.
Nonsensical information refers to text that, while grammatically correct, lacks meaning or coherence. This can happen when the model generates responses that do not logically fit together or fail to make sense within the context of the query. Such outputs can appear as if they are random or disconnected thoughts.
This type of hallucination occurs when the model produces information that directly contradicts established facts. For example, if a model incorrectly states that a well-known historical figure lived in a different century or provides incorrect data about scientific principles, it results in outputs that conflict with verified knowledge.
Input-conflicting hallucinations are responses generated by the model that diverge from the user's specified task or query. This can occur when the model provides information or responses that are unrelated or irrelevant to the input provided, thus failing to address the user's actual request or context.
Context-conflicting hallucinations involve generating self-contradictory outputs within longer responses. This happens when the model provides information that contradicts earlier parts of its own response or fails to maintain consistency throughout, leading to confusion or conflicting statements within the same output.
Accurate and reliable AI outputs are crucial for the effective application of AI in real-world scenarios. Inaccuracies can lead to significant consequences, including misinformed decisions, legal issues, and reputational damage. For AI to be trusted and widely adopted, ensuring the reliability of its outputs is paramount.
Traditional LLMs, despite their advanced capabilities, often prioritize coherence over factual accuracy. These models generate text based on patterns observed in training data, which can sometimes result in coherent but incorrect outputs. The vast amount of training data, often sourced from the internet, includes inaccuracies, biases, and inconsistencies, further complicating the issue. This limitation makes it challenging to ensure the reliability of their outputs, necessitating advanced methods to enhance accuracy.
In sectors like healthcare, finance, and law, the stakes for accuracy are particularly high. In healthcare, incorrect AI-powered diagnoses can lead to patient harm, while in finance, inaccurate reports can misguide investment decisions. In legal contexts, AI-powered content needs to be meticulously accurate to avoid misrepresentations that could influence legal outcomes.
Retrieval Augmented Generation (RAG) combines the generative capabilities of LLMs with those of external knowledge bases. It enriches the context available to LLMs by integrating relevant, verified information from external sources during the text generation process.
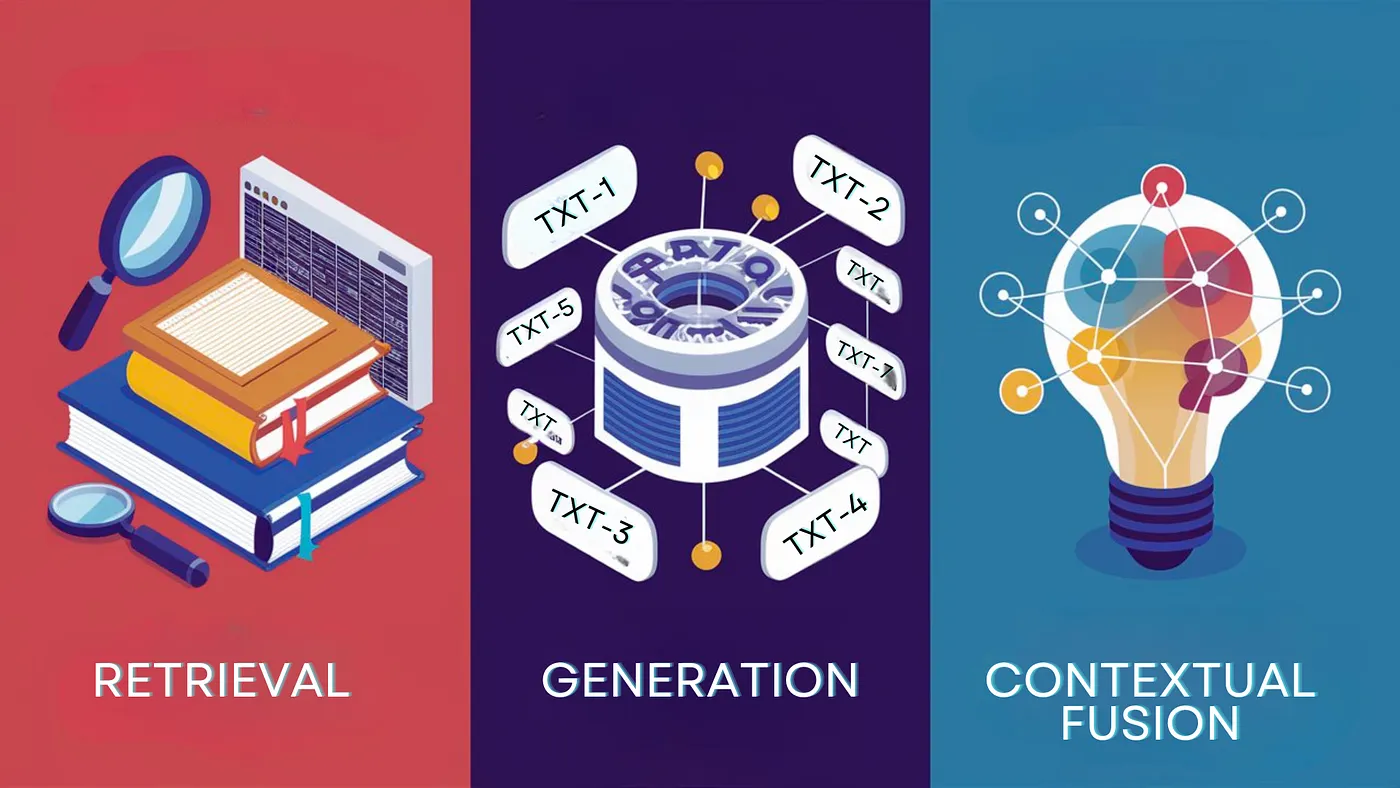
RAG utilizes external knowledge bases, databases, or repositories that contain structured or unstructured data relevant to the input query. When given an input (such as a question or a prompt), the retrieval component searches these external sources to find relevant information. The most relevant pieces of information are selected based on their relevance to the input query.
The retrieved information is then fed into the LLM along with the original input. This combined context allows the LLM to generate text that incorporates the retrieved knowledge. The LLM synthesizes a coherent response by blending the input query and the retrieved information, ensuring that the output is both contextually relevant and factually accurate.
RAG ensures the generated content maintains coherence and factual accuracy by integrating external knowledge. For example, suppose the retrieved information includes recent climate data or relevant scientific theories. In that case, RAG fuses this additional context into the summary, providing a more comprehensive and insightful overview of the topic.
RAG retrieves specific information, minimizing the merging of unrelated details. By accessing targeted and relevant external sources, RAG ensures that the information integrated into the response is directly related to the query, reducing the risk of conflating multiple sources.
Integrates verified data from external sources, correcting inaccuracies. By grounding the generated text in external, verified knowledge, RAG helps correct factual inaccuracies that may arise from the LLM's training data.
Enhances coherence by blending retrieved data with the input context. The contextual fusion of retrieved data ensures that the generated responses are coherent and meaningful, reducing the likelihood of generating nonsensical information.
Aligns generated content with factual and task-specific information, reducing inconsistencies. By integrating external knowledge, RAG ensures that the generated text does not contradict facts or deviate from the user's specified task.
RAG significantly improves the accuracy of AI-powered content by grounding it in verified external knowledge. This ensures that the outputs are factually correct and reliable.
By leveraging external knowledge, RAG mitigates the occurrence of hallucinations, leading to more trustworthy text generation. The integration of external data provides a solid foundation for the generated content, reducing the likelihood of errors.
RAG enriches the input context with relevant information, enabling LLMs to produce more coherent and contextually appropriate responses. This ensures that the generated content is not only accurate but also relevant and comprehensive.
RAG's effectiveness relies on the availability and reliability of external knowledge sources. Any bias or inaccuracies in these sources can affect the quality of the generated text. Ensuring the credibility and reliability of these external sources is crucial.
The retrieval and integration processes add computational overhead, potentially increasing latency and resource requirements. Implementing RAG requires sufficient computational resources to handle the additional complexity.
Managing large datasets and queries effectively while maintaining performance can be complex. Scaling RAG to handle extensive data and numerous queries requires careful planning and optimization.
Fine-tuning involves adjusting the parameters of pre-trained language models to better suit specific tasks or domains. By fine-tuning the model on task-specific datasets, developers can enhance its performance and reduce the likelihood of hallucinations. For example, fine-tuning an LLM on a dataset of medical texts could improve its accuracy in generating medical reports or diagnoses.
Advanced prompting techniques involve providing the model with carefully crafted prompts or instructions to guide its generation process. These prompts can help steer the model towards producing more accurate and contextually relevant outputs. For example, providing the LLM with structured prompts that specify the desired format or content of the generated text can help reduce hallucinations and improve output quality.
Adversarial training involves training the LLM alongside another model known as a discriminator, which evaluates the generated outputs for accuracy and coherence. By iteratively refining the LLM based on feedback from the discriminator, developers can improve its performance and reduce hallucination tendencies. This approach enhances the robustness and reliability of the generated text.
Ensemble methods involve combining multiple LLMs or models trained on different datasets to generate diverse outputs. By leveraging the collective intelligence of diverse models, developers can reduce the risk of hallucinations and improve the overall robustness of the generated text. Ensemble methods provide a broader perspective and mitigate the limitations of individual models.
LLM hallucinations pose a significant challenge to the reliability of AI systems. Retrieval Augmented Generation (RAG) offers a promising solution by integrating external knowledge into the text generation process, reducing hallucinations and enhancing accuracy. By grounding AI-powered content in verified information, RAG ensures more reliable and trustworthy outputs, making it a valuable tool for various applications across different sectors. Advancements in RAG and complementary techniques will continue to improve the reliability of LLMs, driving innovation in AI applications. As AI technology evolves, integrating diverse approaches to enhance accuracy and reduce hallucinations will be crucial for the widespread adoption of AI systems. Explore RAG and other techniques to enhance the accuracy of your AI applications. Implementing advanced methods like RAG can significantly improve the reliability of AI-powered content, fostering trust and confidence in AI systems.
Subscribe to get the latest updates and trends in AI, automation, and intelligent solutions — directly in your inbox.
Discover cutting-edge LLM-powered solutions transforming industries with advanced natural language processing and AI innovation.
Empower your AI journey with our expert consultants, tailored strategies, and innovative solutions.