Generative Artificial Intelligence (Gen AI) has emerged as a transformative force, driving innovation across various domains. Its applications range from natural language processing to image generation, making it a hot topic in the tech world. In this blog, we will embark on a journey to demystify Generative AI, exploring its scope, understanding the role of Large Language Models (LLMs), delving into the intricacies of their architecture, and addressing the challenges they face.

Generative AI encompasses a wide array of technologies designed to generate content, whether it be text, images, or even entire narratives. This broad scope has led to its integration into numerous fields, including creative arts, healthcare, finance, and beyond. The ability to create human-like content has opened up new possibilities, from enhancing user experiences to aiding in decision-making processes.
Large Language Models (LLMs), such as GPT-3, have become synonymous with Generative AI due to their remarkable ability to generate coherent and contextually relevant text. However, it's crucial to note that not all LLMs are strictly generative in nature. While they excel at generating human-like text based on input prompts, they lack the true creativity and understanding inherent in some other forms of Generative AI, such as those used in artistic endeavors or content creation.
LLMs generate content based on patterns and information present in their training data. They lack true creativity and the ability to generate entirely novel ideas, concepts, or expressions.
Despite their impressive language generation capabilities, LLMs do not possess a deep understanding of context or the ability to infer nuanced meanings from input.
LLMs heavily rely on the training data they are exposed to. Biases present in the data can lead to biased outputs, and the model may inadvertently perpetuate stereotypes and inaccuracies present in the training set.
While LLMs can provide information present in their training data, they lack the capability to generate new knowledge or information that goes beyond what they have learned.
LLMs can be sensitive to slight changes in input phrasing, leading to varying and sometimes unexpected outputs. Adversarial inputs, intentionally crafted to deceive the model, can exploit these vulnerabilities.
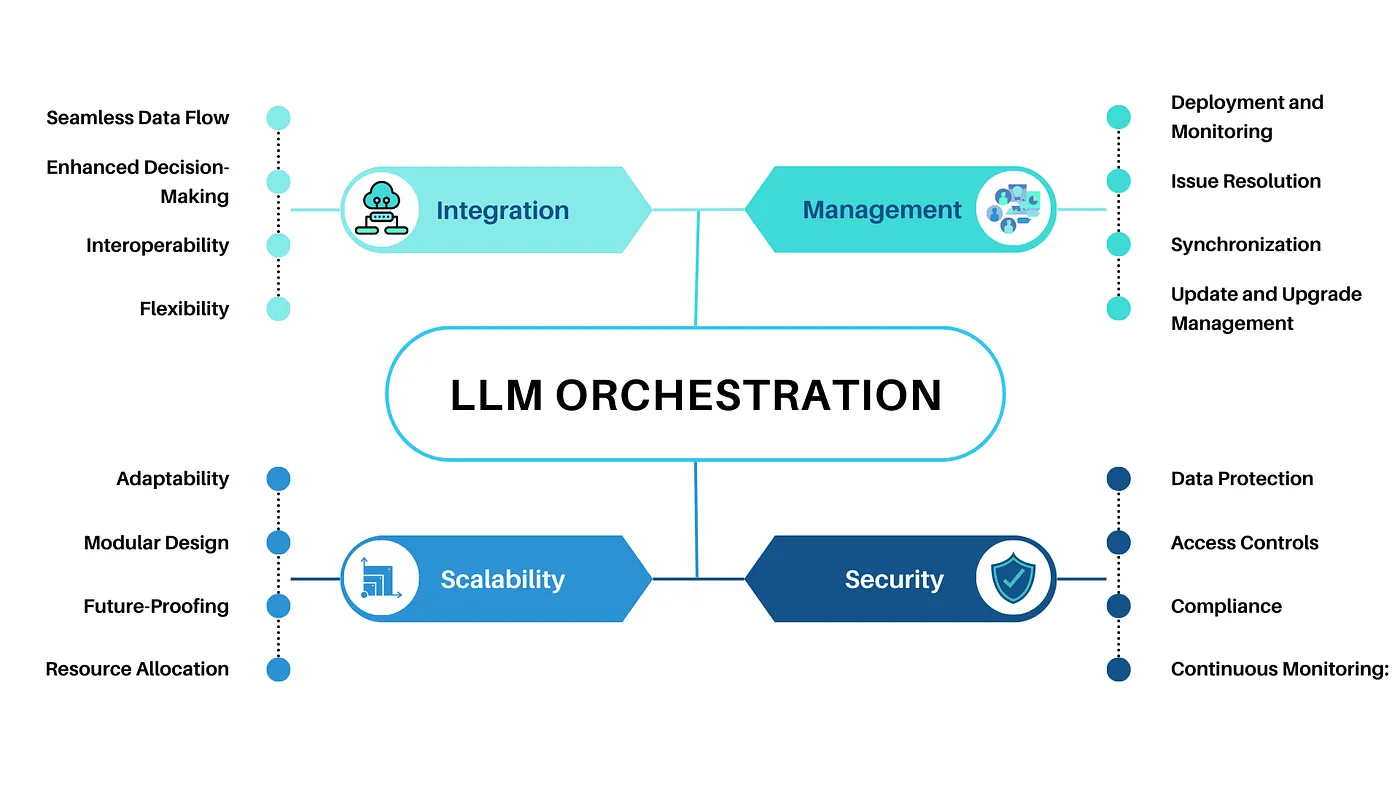
CAI Stack intersect with LLMs, catalyzing their capabilities and mitigating inherent limitations. This integration unfolds in various domains, amplifying the effectiveness of both technologies.
CAI Stack augment LLMs in comprehending and generating human-like text, revolutionizing chatbots, language translation, and text summarization.
LLMs, bolstered by CAI Stack, excel in content generation tasks, aiding in writing assistance, content summarization, and creative writing prompts.
Leveraging CAI Stack, LLMs proficiently handle information retrieval tasks such as question answering, contributing to their efficacy in handling diverse queries.
CAI Stack integrated with LLMs prove invaluable in educational settings, assisting in language learning, content generation, and research endeavors.
The development and improvement of LLMs have paved the way for advancements in natural language processing, inspiring further research and innovation.
To understand the mechanics behind Large Language Models (LLMs), it's crucial to delve into the Transformer architecture. Introduced by Vaswani et al. in their seminal paper, 'Attention is All You Need,' Transformers have revolutionized the field of natural language processing.
At the core of the Transformer architecture is the attention mechanism, which enables the model to focus on specific parts of the input sequence while generating output. This allows for the parallel processing of input sequences, where the model considers all words simultaneously. This approach significantly accelerates both training and inference, contributing to the impressive performance of LLMs.
Despite their remarkable capabilities, LLMs face significant challenges related to robustness. These models can be sensitive to the phrasing of input prompts and may generate biased or inappropriate responses. The models' lack of genuine contextual understanding and world knowledge often results in inconsistent and unreliable outputs.
One major issue stems from the biases present in the training data. If the data used to train these models contains biases, the models are likely to reflect and even exacerbate those biases in their outputs.
The problem is further compounded by the models' reliance on memorized patterns rather than true comprehension.
To address these challenges, researchers are exploring various techniques. Adversarial training, for instance, involves exposing models to intentionally crafted inputs to enhance their resilience against bias and manipulation. Additionally, integrating external knowledge bases and fact-checking mechanisms during inference can help improve the accuracy and reliability of model outputs.
The release of GPT-4 marks a significant advancement in natural language processing. With a larger number of parameters and enhanced training methodologies, GPT-4 demonstrates improved performance in understanding context, generating coherent text, and handling nuanced prompts. While the Transformer architecture remains foundational, refinements in training strategies have further elevated the capabilities of GPT-4.
The optimization process for Transformers involves tuning model parameters to minimize discrepancies between predicted and actual outputs. This iterative adjustment process is crucial for improving model performance. Advanced optimization techniques and architectures are being developed to efficiently handle the scale and complexity of LLMs.
Future advancements in optimizing LLMs are likely to focus on developing adaptive optimizers that adjust learning rates dynamically and exploring novel algorithms that offer robust convergence.
Model parallelism and distributed training are becoming essential for managing the computational demands of large-scale models.
The optimization of Transformers, and by extension LLMs, involves fine-tuning model parameters to minimize loss and enhance prediction accuracy. As the field continues to evolve, the focus will be on developing sophisticated techniques to handle the complexities of increasingly large models.
Subscribe to get the latest updates and trends in AI, automation, and intelligent solutions — directly in your inbox.
Discover cutting-edge LLM-powered solutions transforming industries with advanced natural language processing and AI innovation.
Empower your AI journey with our expert consultants, tailored strategies, and innovative solutions.